In this video, I’ve tried explaining 2 very common use cases which every other Kubernetes app developers worry about and how Telepresence can come to your rescue!
I’ll love to hear from you, so please leave behind you valuable comments and if you liked the video, please like/subscribe!
Cloud providers such as AWS, Azure & GCP introduces notion of server less services which allows developers to build applications at scale with less infrastructure complexities. Developers can publish services within minutes without thinking about resource & infrastructure allocations. These new applications often have API services.
If not done right, the ephemeral nature of such server less applications often result them to go undetected. This leads to the creation of Shadow APIs. There are many other scenarios which could lead to introduction of Shadow APIs in your org.
Fundamentally, Shadow APIs are the services that your company uses, but doesn’t/couldn’t get tracked for one or other reasons. You may not even know they ever existed!
Threat the shadow APIs possesses!
The biggest problem with shadow APIs is the very nature of them being unknown! They could fail at any time to meet your org’s compliance standards, & even put your user’s data at risk—all without your knowledge! There are many examples where simple specification validation may have avoided significant security incidents such as Panera Bread & Uber!
How to detect shadow APIs?
The first step in avoiding shadow APIs is to discover the ones in your org! The goal is to increase visibility into your API reliance across the entire development & product organisation.
API discovery done right can help aligning both technical & non-technical stakeholders so that everyone has better insight into the state of API usage within an organisation and thus avoiding the perils of shadow APIs!
CockroachDB is a CP (consistent and partition tolerant) distributed persistent data-store system which supports ACID transactional semantics & versioned values as first class citizen. The primary goal is global consistency & survivability, hence the name of the database. CockroachDB aims to tolerate disk, machine. rack and even datacenter failures with minimal latency disruption & no manual intervention. It scales linearly. External API is a standard SQL with extensions whereas at the lowest level, CockroachDB is a key-value store.
CP (consistency & partition tolerance) means that, in the presence of partitions, the system will become unavailable rather than do anything which might cause inconsistent results.
Database internals
Layered Architecture
Storage layer in depth
RocksDB
In context with CockroachDB, the storage engine’s responsibility is providing –
Atomicity
Durability
Performance
CockroachDB uses RocksDB as part of it’s storage engine. RocksDB is a single node key-value store designed based on LSM (Log Structured Merge trees).
SSTable
In RocksDB, keys & values are stored as sorted strings in files called “SSTables” (Sorted Set Tables) onto disk.
SSTables are arranged in several level.The levels are structured roughly so that each level is in total 10x as large as the level above it. When the new keys arrive at the highest layer and gets larger and larger and hits a threshold, they get compacted into fewer but larger SSTables one level lower.
SSTables are non-overlaping i.e. one SSTable might contain keys covering the range (a,b), then next (b,d) and so on. The key space does overlap between levels i.e. if there are 2 levels, the first might have 2 SSTables covering the earlier ranges but the second level might have a single SSTable over the keyspace (a,e). So, looking for a key “ari” will require 2 SSTable lookups: the (a,b) SSTable in Level 1 and the (a,e) SSTable in Level 2.
Each SSTable is internally sorted so looksup within an SSTable take log(n) time. SSTables store their keys in blocks and have an internal index so even though a single range may be very large, only the index and relevant block needs to be loaded into memory.
Memtable
Every update to RocksDB are written to 2 places –
Memtable
WAL
Memtable is an in-memory data-structure holding data before they are flushed to SSTables. It serves both reads & writes. New writes always inserts data to memtable and reads has to query memtable before reading from SSTables as the data in memtables are newer. Once a memtable reaches threshold, it becomes immutable and replaced by a new memtable. A background thread takes care of flushing this full memtable to disk (SSTable) after which this memtable is destroyed. CockroachDB uses skiplist based memtables.
WAL
Write Ahead Logs are unsorted logs which gets replayed on the event of a failure to recover the data in the memtable which is necessary to restore the database to the original state. RocksDB guarantees process crash consistently by flushing the WAL after every user write. WAL gets created on disk to persist all writes once the db is opened and it keeps recording all the writes until it reaches a max size. Upon flush at this stage, a new WAL gets created and older WAL no longer records the writes. Deletion of this old WAL is delayed and not immediate. So, in summary only when all the data in WAL is flushed to SSTables, only then they gets purged from disk latter on.
Data Distribution In Cluster
For any production deployment, it is guaranteed that over the period of time, data will grow for n-number of reasons. So, it would not be wrong to assume that these entire data are not going to fit on a single machine. Given that, there are 2 key aspects to consider –
How could then these data be distributed across multiple machines?
Given, the data are distributed across machines, how do we find a piece of data?
In general, there are 2 primary approaches for this –
Hashing
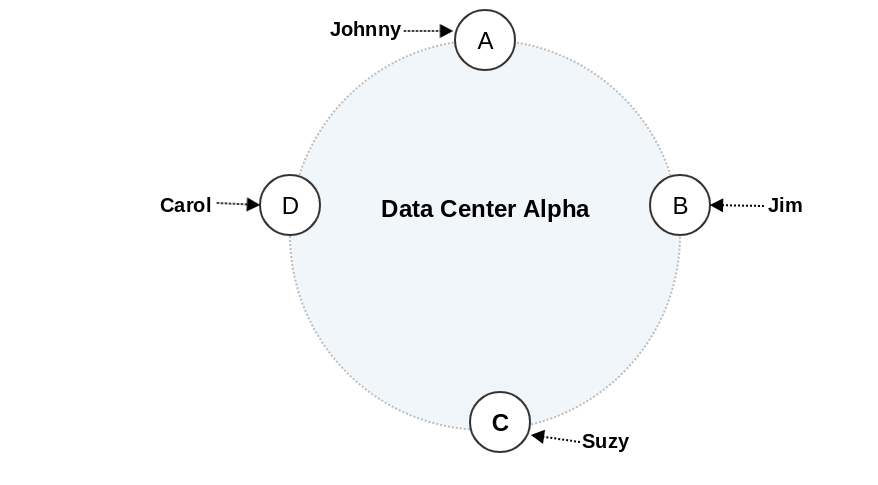
In this approach an efficient deterministic hashing algorithm is used to calculate hash value of a record key which is then mapped to a machine in a cluster. This approach makes locating a data by key damn straight. However, doing a range scan is not straightforward & inefficient as hash functions doesn’t maintain ordering of data.
NoSQL Cassandra database using this approach for data distribution in it’s cluster.
Name (Key)
Age
Car
Gender
jim
36
camaro
M
carol
37
bmw
F
johnny
12
M
suzy
10
F
Node
Start Range
End Range
Partition Key
Hash Value
A
-9223372036854775808
-4611686018427387904
johnny
-6723372854036780875
B
-4611686018427387903
-1
jim
-2245462676723223822
C
0
4611686018427387903
suzy
1168604627387940318
D
4611686018427387904
9223372036854775807
carol
7723358927203680754
Order-preserving
In this approach, data is laid out in alphabetical order & spitted out in evenly chunks which are then distributed across all the machines in a cluster. With this approach range scans are efficient even if there could be a need to talk to multiple machines in a cluster. However, the downside of this approach is making it hard to deterministacally locate a data by it’s key. This downside is addressed in this approach by adding a range index on top to track which range is locating in the cluster & in which machine in a given point of time.
When a new machine is added to the cluster, there exists a “control process”, living either outside the cluster or inside the database system, detects imbalance of data in the cluster, so it initiates moving of data across the machines to the new node in a way that the cluster is now balanced. On the contrary, when an existing machine in a cluster fails, the same process takes care of balancing the cluster in the same way as former.
CockroachDB uses this approach for data distribution in it’s cluster.
Consistency & Data Replication In Cluster
Failure of a machine in a cluster is something indispensable in a distributed system, so it is always recommended to have multiple copies of data in a cluster. This brings an aspect for consideration viz. how to keep remote copies of data in sync or how to do conflict resolution when one machine gives one version of a data whereas the other machine gives another version.
SQL databases handles this through –
Cold backups – But this never really guarantees the fact that the backups are fully up-to-date.
Primary-Secondary replications – In this approach, all writes go to the “Primary” machine and then these writes are pushed from the “Primary” to “Secondary” instances. These pushes to “Secondary” machines could be either “synchronously” or “asynchronously” done. With synchronous replication approach, all writes get delayed waiting for the secondary to acknowledge. Also, more complication when “Secondary” machine fails. With asynchronous replication approach, “Secondary” machine lags behind “Primary” and in case of fail-over, there could be loss of recent writes.
Cassandra NoSQL database handles this through either one of the following approach –
Last write wins – In this approach, whenever a data is requested by a client, the requested data is looked up in the cluster. Supposedly when 2 out of 3 machines in the cluster returns 2 different versions of the requested data, then Cassandra chooses to return the version of data which has the latest timestamp associated with it. Internally it also initiates a process called as “read repair” which ensures that the machine which has inconsistent version of the data updates to the apt version.
Quorum reads & writes – In this approach, whenever a data is requested or written, Cassandra requires majority of the machine in the cluster to acknowledge before it could consider that operation to be successful.
CockroachDB database handles this in a similar approach as Cassandra. The distributed consensus protocol used by CockroachDB is “Raft”. At a high level, this means there are odd number of machines in a cluster, often 3 or 5 and a write is considered to be successful only when a quorum viz. majority of the machines in the cluster have actually written the data to it.
“Raft” is based around leader election. There is a set of replicas in a cluster which elects a leader.That leader appends incoming write request to a sequential log and assign index to each command. This sequential log is then replicates from leader to followers. The write request is considered to be successful when majority of the machines in the cluster have written onto their disk.
In case of fail-over scenario –
When a write request is being handled by a leader & the leader machine dies before it replicates the data in the cluster. In this scenario the data is written to the leader machine but there has not been majority of machines in the cluster acknowledging the write, so in this scenario the write request is considered to be unsuccessful.
When a read request is being handled by a leader & the leader machine dies before getting an acknowledgement from majority of the machines in the cluster. In this scenario, a new leader is elected as the old one is down and this machine doesn’t have the data. Then the leader requests the follower if it has the data but the follower too will not have the data as it wasn’t successful as explained in the former section. In such scenario, the new leader will ask the previous leader to remove the data from it’s disk and it responds back the client that the data doesn’t exists.
In practice, CockroachDB runs one consensus group per range of data.
Transactions
Transactions are bit tricky in a distributed database system especially in when coordination is needed across multiple machines in the cluster.
CockroachDB achieves transaction through –
Transaction atomicity is bootstrapped on top of Raft atomicity. Each transaction is tagged with something called as transaction id when they are written to disk & these writes are not visible to reads as they are still tagged to the marker. These transaction record is written to consensus group as write to consensus group (raft group) is always atomic.
Transaction isolation uses pure MVCC (Multi Version Concurrency Control) with conflict resolution. With this approach every time it stores a data in disk it associates a timestamp with it. The timestamp represents the timestamp of the transaction. Anytime when updating the row, instead of overwriting it, just create a new row next to the old row with a newer timestamp. Anyone who needs to read the data, needs to read the row associated with the latest timestamp. So, concurrent transactions do not interfere with each other.
Considering the following diagram –
When a transaction is started, a transaction record is created with status as “PENDING”. This record is usually placed in the same machine as the machine to which the first record is going to be modified i.e. in the following scenario, transaction record would be created in machine 1 as the first record going to be modified is “cherry” which is going to be updated in the machine 1 as shown in the below diagram. When cherry is written to machine 1, a marker is also created along side with transaction id i.e. in this scenario it is “txn 1”. Similarly, “mango” is written to machine 2 along side the transaction id. When the transaction is committed, it does a single consensus write and flips the status of the transaction record to “COMMITTED”. At this point, any new transaction that wants to read this data gets the transaction id and checks the status from transaction record and as being COMMITTED is able to get to see the new committed data.
After the transaction completes, CockroachDB proactively goes and cleans up the associated transaction id with the record to ensure reads do not require to check the transaction record for the status of the transaction every time. At this point of time, the transaction record is as well removed as it is no more required.
In case of fail-over, assume both transactions are trying to update the same record. From the following diagram, both transaction 1 and 2 are trying to update the record “cherry”. In this situation, transaction 2 would first check if transaction 1 is actual pending or committed. In case it is still pending state, then it pushes or aborts the transaction 1 and then updates the transaction id associated with the record to it’s transaction id. Once the transaction is done, then it updates the transaction record and cleans up the intent as well as the transaction record.failover_transaction_cockroachdb
Audit Logging
Currently this is an experimental feature which is subject to change in future.
CockroachDB has the capability to audit log detailed information about queries being executed in the system. To turn on the auditing for a table, EXPERIMENTAL_AUDIT sub-command of ALTER TABLE could be used in the following way –
ALTER TABLE <TABLE_NAME> EXPERIMENTAL_AUDIT SET READ WRITE
To turn on auditing for more than one table, a separate ALTER statement needs to be issued for each table.
By default, the active audit log file is name as “cockroach-sql-audit.log” and is stored in CockroachDB’s standard log directory. To store the audit log files in a different directory, –sql-audit-dir flag could be passed to “cockroach start” command. Like other log files, it’s rotated according to the –log-file-max-size setting.
The format of audit log would be something like below –
I180321 20:54:21.381565 351 sql/exec_log.go:163 [n1,client=127.0.0.1:60754,user=root] 2 exec "cockroach sql" {"customers"[76]:READWRITE} "ALTER TABLE customers EXPERIMENTAL_AUDIT SET READ WRITE" {} 4.811 0 OK
I180321 20:54:26.315985 351 sql/exec_log.go:163 [n1,client=127.0.0.1:60754,user=root] 3 exec "cockroach sql" {"customers"[76]:READWRITE} "INSERT INTO customers(\"name\", address, national_id, telephone, email) VALUES ('Pritchard M. Cleveland', '23 Crooked Lane, Garden City, NY USA 11536', 778124477, 12125552000, 'pritchmeister@aol.com')" {} 6.319 1 OK
I180321 20:54:30.080592 351 sql/exec_log.go:163 [n1,client=127.0.0.1:60754,user=root] 4 exec "cockroach sql" {"customers"[76]:READWRITE} "INSERT INTO customers(\"name\", address, national_id, telephone, email) VALUES ('Vainglorious K. Snerptwiddle III', '44 Straight Narrows, Garden City, NY USA 11536', 899127890, 16465552000, 'snerp@snerpy.net')" {} 2.809 1 OK
I180321 20:54:39.377395 351 sql/exec_log.go:163 [n1,client=127.0.0.1:60754,user=root] 5 exec "cockroach sql" {"customers"[76]:READ} "SELECT * FROM customers" {} 1.236 2 OK
Opened feature requests to CockroachDB development team
I’ve created the following feature request –
ISSUE-37209 : Enhancing audit logging in CockroachDB
Core Changefeed
Currently this is an experimental feature which is subject to change in future.
This is a new experimental feature with CockroachDB version 19.1.0 which provides row-level change subscriptions. A core changefeed streams changes for the watched rows indefinitely until the underlying connection is closed or the changefeed query is canceled. The changefeed could only be created by superusers i.e. members of the admin role.
The enterprise variant of CockroachDB provides ability to directly connect changefeed to Kafka. In case of core variant of CockroachDB, an application could have a dedicated connection to CockroachDB and consume changefeed data.
Below is the command to create a core changefeed. Options description could be found over here.
EXPERIMENTAL CHANGEFEED FOR table_name [ WITH (option [= value] [, ...]) ];
Online Schema Changes
CockroachDB allows changes to schema elements like columns & indexes without forcing a downtime. This ensures changes to a table schema happens while the database is running. The schema change runs as a background job without holding locks on the underlying table data. This enables application to be able to query from table normally with no effect on read/write latency. Technical details on this is achieved could be found here.
Fault Tolerance
CockroachDB survives fault tolerance through –
Data replication
CockroachDB can survive (n-1)/2 machines failures in a cluster where n is the replication factor of a piece of data.
Automated Repair
Once a machine in a cluster has been down for 5 minutes, the cluster repairs under-replicated ranges, as long as other nodes have space. While doing this the cluster ensures that not more than 1 replica of a range is on a single machine.
Cleanup
Like any distributed database system, in CockroachDB, data cleanup/deletion for disk space claim doesn’t happen immediately. CockroachDB keeps the deleted data in disk for “gc.ttlseconds” which is by default 25 hours. This value is set for the replication zone. If disk usage is a concern, the solution is to reduce this parameter for the zone to a lower than default value which will cause garbage collection to clean up deleted objects (rows/tables) more frequently.
Like any other distributed database system, it is advised such that no queries results in scanning across tables that have lots of deleted rows which are yet to be garbage collected. In such situations it is always advised to reduce the ttlseconds parameters to clean up deleted rows more frequently. However, it is not recommended to set this below 10 minutes as doing so will cause problems for long running queries.
Scaling
CockroachDB scales horizontally with minimal operator overhead. Adding capacity is as easy as pointing a new node at the running cluster. At the key-value level, CockroachDB starts off with a single,empty range. As data is put in, this single range eventually reaches a threshold (64 MB by default) upon which data is split into 2 ranges, each covering a contiguous segment of the entire key-value space. This process continues indefinitely as new data flows in, existing ranges continues to split into new ranges aiming to keep a relatively small and consistent range size.
When the cluster spans multiple nodes, newly split ranges are automatically rebalanced to nodes with more capacity. CockroachDB communicates opportunities for rebalancing using a peer-to-peer gossip protocol by which nodes exchange network addresses, store capacity and other vital information.
Backup & Restore
The process for backup and restore depends on the licensing.
Open Source Core CockroachDB
In case of open source variant, a “core backup” could be performed which is pretty much dumping and restoring everything.
This is done through “cockroach dump” command which dumps all the tables in the database to a new file.
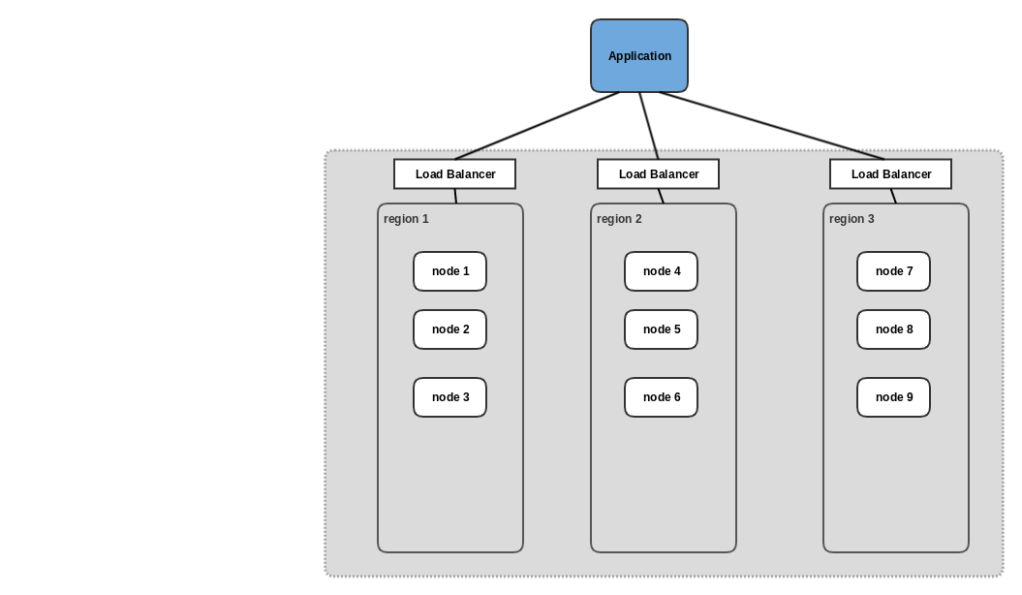
For a cluster availability, a data-center outage is not acceptable. This is where a “multi-region cluster” is useful and is available with open source CockroachDB.
A multi-region cluster is comprised of multiple data-centers in different regions, each with multiple nodes. CockroachDB will automatically try to diversify replica placement across localities. This setup is used when the application is not a SLA-sensitive or write-performance is least cared for as performance of writes could be as fast as the slowest quorum between 2 regions and reads might result in a network round-trip from one region to another adding to latency.
Following at a high level shows 3 nodes across 3 data centers which are not using partitioning (licensed feature) –
Opensource (core) Versus Commercial (enterprise) Comparison
The most up to date for this section could be found here.
Clustered Installation
Local Workstation
For local workstation installation, cockroachDB binaries could be downloaded from here. Different OS variants could be found in the same link.
Kubernetes
The following resources could be used to install cockroachDB in Kubernetes –
Installation of the above chart by default will start a 3 node cockroachDB cluster in k8s. Below is a screenshot from k8s dashboard –
Monitoring
Using Admin UI
By default cockroach db installation also brings an administrative UI also known as cockroach console which provides all basic needs for monitoring the cockroach db cluster’s health. It provides all basic metrics for monitoring. Below are few screenshots of the admin UI.
Using Grafana
TBD
Connecting Clients
Go Clients
Postgresdb driver library for golang pq can be used for accessing CockroachDB. Below is a simple client in golang connecting and performing basic operations –
package cockroachdb
import (
"database/sql"
"fmt"
"time"
_ "github.com/lib/pq"
"gerrit.ext.net.nokia.com/AANM/go/pkg/logging"
)
var log = logging.NewLogger()
func Store(dbUsername string, dbAddrs string, dbName string) {
// Connect to the "cockroach" database.
db, err := sql.Open("postgres",
"postgresql://"+dbUsername+"@"+dbAddrs+"/"+dbName+"?sslmode=disable")
if err != nil {
log.Fatal("error connecting to the database: ", err)
}
defer db.Close()
// Create the "perf" table.
if _, err := db.Exec(
"CREATE TABLE IF NOT EXISTS perf (id INT PRIMARY KEY, occurance_id INT, occured_at TIMESTAMP)"); err != nil {
log.Fatal(err)
}
// Insert two rows into the "perf" table.
if _, err := db.Exec(
"INSERT INTO perf (id, occurance_id, occured_at) VALUES (1, 1000, TIMESTAMP '2019-04-27T10:10:10.555555'), (2, 250, TIMESTAMP '2019-04-26T10:10:10.555555')"); err != nil {
log.Fatal(err)
}
// Print out.
rows, err := db.Query("SELECT id, occurance_id, occured_at FROM perf")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
fmt.Println("Data in perf:")
for rows.Next() {
var id, occurance_id int
var occured_at time.Time
if err := rows.Scan(&id, &occurance_id, &occured_at); err != nil {
log.Fatal(err)
}
fmt.Printf("%d %d %v\n", id, occurance_id, occured_at)
}
}
Database schema migration
The existing golang-migrate approach for database schema migrations could be re-used for migrating database schema in CockroachDB. More on this here.
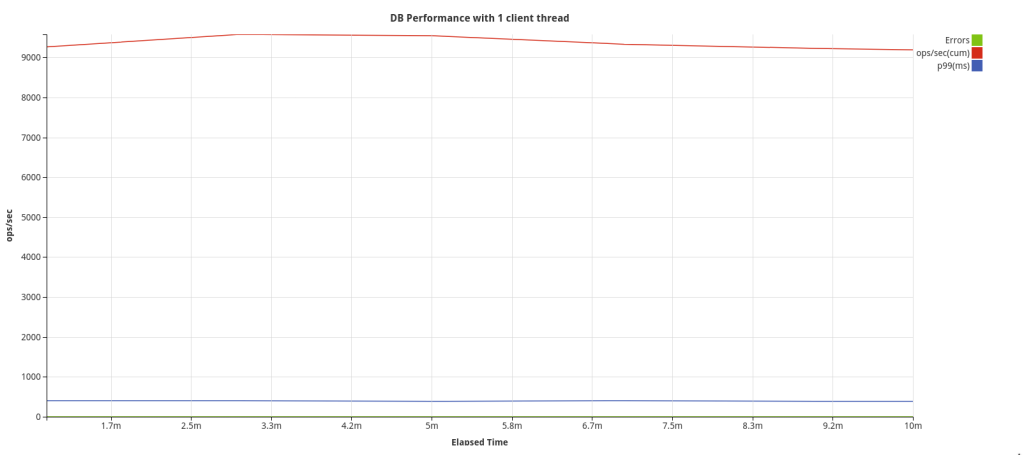
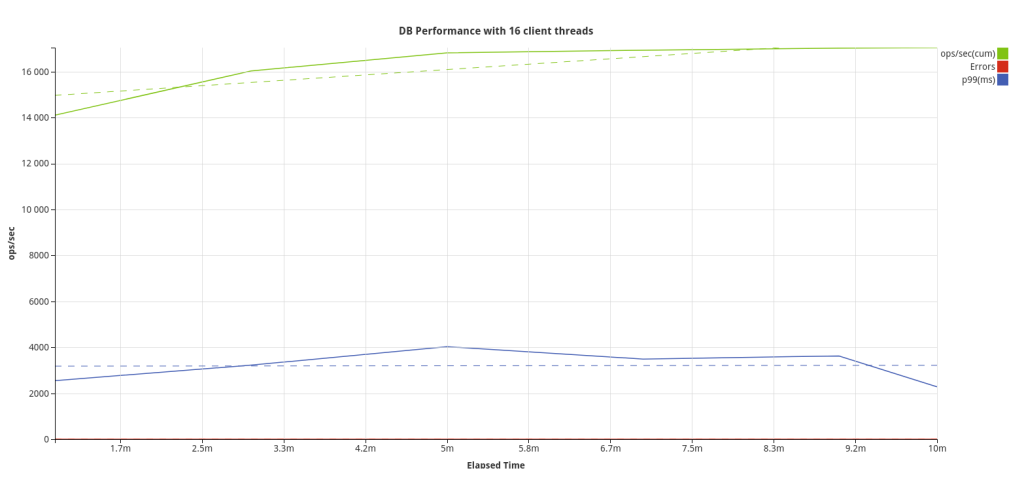
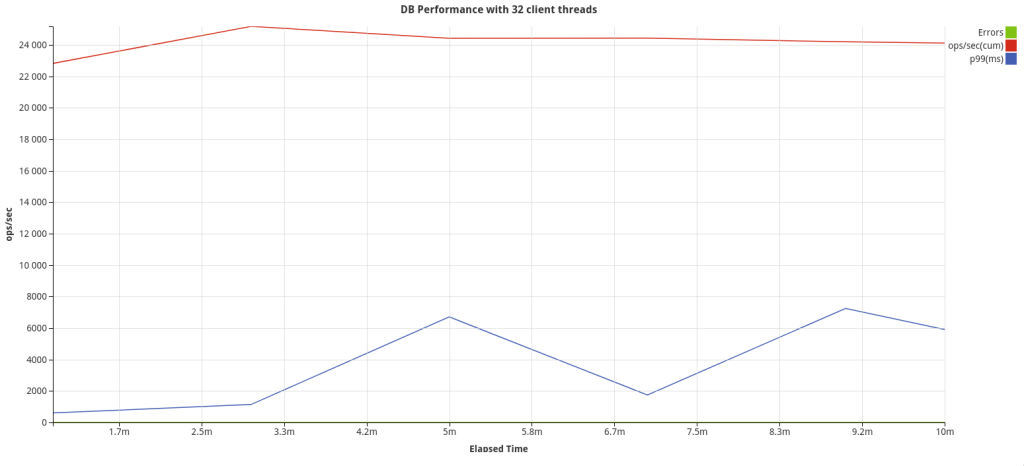
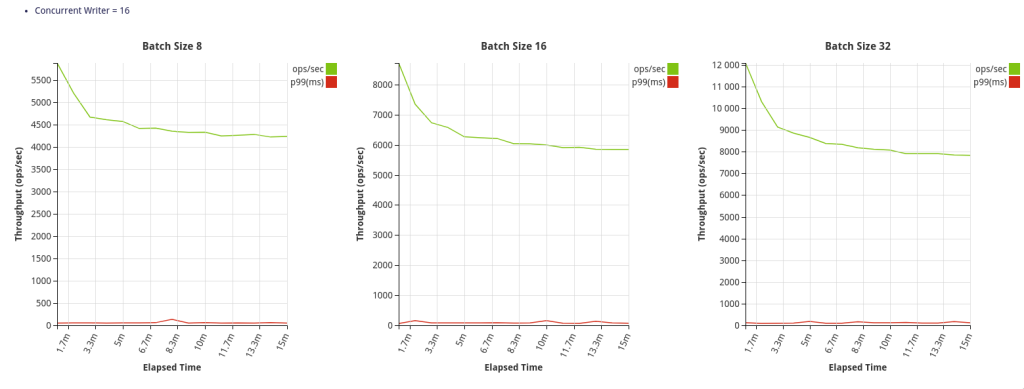
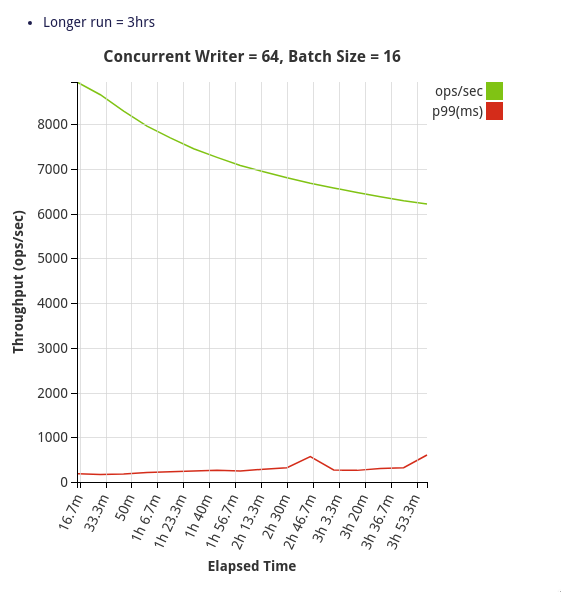
Benchmark
Configuration –
3 node CockroachDB cluster
Secured Deployment
Golang Client
Batch size – 4096
Table schema –
create table ABCD_TBL
(
id bigint not null,
ts timestamp,
person VARCHAR (32) not null,
attributes jsonb,
PRIMARY KEY ( ID )
);
An object oriented system integrates the data & it’s behavior using the concept of an object. An object is an abstract data type that has state & behavior.
The fundamental concepts of object orientation are alive in Go. Go utilizes structs as the union of data & behavior. Through composition, has-a relationships can be established between Structs to minimize code repetition while staying clear of the brittle mess that is inheritance. Go uses interfaces to establish is-a relationships between types without unnecessary and counteractive declarations.
Objects In Go
While Go doesn’t have something called object, it does have a type that matches the same definition of a data structure that integrates both data & behavior. In Go, this is called as “struct”.
type rect struct {
width int
height int
}
func (r *rect) area() int {
return r.width * r.height
}
func main() {
r := rect{width: 10, height: 20
fmt.Println("Area: " + r.area())
}
Inheritance in Go
Go is intentionally designed without any inheritance at all. This doesn’t mean that objects viz. struct values do not have relationships. Go authors have chosen to use an alternative mechanism to convey relationships which resolves decade old issues and arguments around inheritance.
So, what really are the arguments around inheritance? To understand this may be its worth to quote James Gosling’s (Java’s inventor) quote in one of the Q&A –
During the memorable Q&A session, someone asked him: “If you could do Java over again, what would you change?” “I’d leave out classes,” he replied. After the laughter died down, he explained that the real problem wasn’t classes per se, but rather implementation inheritance (the extends relationship). Interface inheritance (the implements relationship) is preferable. You should avoid implementation inheritance whenever possible.
Loosing Flexibility
Explicit use of concrete class names locks you into specific implementations making down the line changes unnecessarily difficult. This hinders the possibility to write code in such a way that you can incorporate newly discovered requirements into the existing code as painlessly possible.
Coupling
Inheritance introduces coupling. As a designer, you should strive to minimize such coupling altogether. In an implementation-inheritance system that uses extends, the derived classes are very tightly coupled to base classes, and this close connection is undesirable. Base classes are considered to fragile because you can modify a base class in a seemingly safe way, but this new behavior, when inherited by derived classes, might cause the derived classes to malfunction. You simply can’t tell whether a base class change is safe by examining the base’s class methods in isolation; you must check all code that uses both base class & derived class objects too!
In short, Inheritance Is Best Left Out!
Object composition in Go
Go uses embedded types to implement the principle of object composition. Go permits you to embed a struct within a struct giving them a has-a relationship.
type Person struct {
Name string
Address Address
}
type Address struct {
Number string
Street string
City string
State string
Zip string
}
func (p *Person) Talk() {
fmt.Println("Hi, my name is", p.Name)
}
func (p *Person) Location() {
fmt.Println("I’m at", p.Address.Number, p.Address.Street, p.Address.City, p.Address.State, p.Address.Zip)
}
func main() {
p := Person{
Name: "Steve",
Address: Address{
Number: "13",
Street: "Main",
City: "Gotham",
State: "NY",
Zip: "01313",
},
}
p.Talk()
p.Location()
}
Subtyping in Go
Pseudo subtyping
The pseudo is-a relationship works via anonymous fields.
Let’s use the following statement to depict this. A person can talk. A citizen is a person therefore a citizen can talk.
type Citizen struct {
Country string
Person
}
func (c *Citizen) Nationality() {
fmt.Println(c.Name, "is a citizen of", c.Country)
}
func main() {
c := Citizen{}
c.Name = "Steve"
c.Country = "America"
c.Talk()
c.Nationality()
}
However, anonymous fields are not true subtyping -Anonymous fields are still accessible as if they were embedded.
Anonymous fields are still accessible as if they were embedded.
func main() {
c := Citizen{}
c.Name = "Steve"
c.Country = "America"
c.Talk() // <- Notice both are accessible
c.Person.Talk() // <- Notice both are accessible
c.Nationality()
}
True subtyping becomes the parent
package main
type A struct{
}
type B struct {
A //B is-a A
}
func save(A) {
//do something
}
func main() {
b := B
save(&b); //OOOPS! b IS NOT A
}
True subtyping
Subtyping is the is-a relationship. In Go each type is distinct and nothing can act as another type, but both can adhere to the same interface. Interfaces can be used as input and output of functions & methods and consequently establish an is-a relationship between types.
func SpeakTo(p *Person) {
p.Talk()
}
func main() {
p := Person{Name: "Dave"}
c := Citizen{Person: Person{Name: "Steve"}, Country: "America"}
SpeakTo(&p)
SpeakTo(&c) //cannot use c (type *Citizen) as type *Person in function argument
}
Now adding an interface called “Human” and using that as the input for our speakTo function will work as intended.
type Human interface {
Talk()
}
func SpeakTo(h Human) {
h.Talk()
}
func main() {
p := Person{Name: "Dave"}
c := Citizen{Person: Person{Name: "Steve"}, Country: "America"}
SpeakTo(&p)
SpeakTo(&c)
}












{kind=link}
{kind=link}
{kind=link}